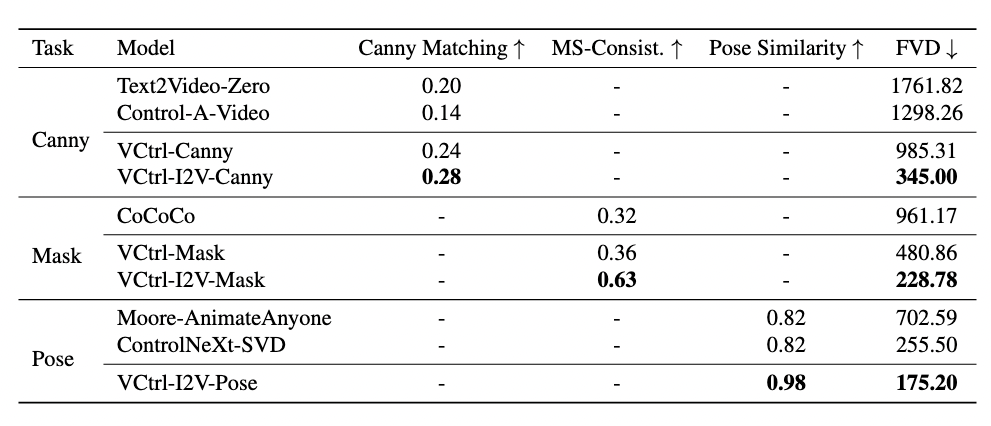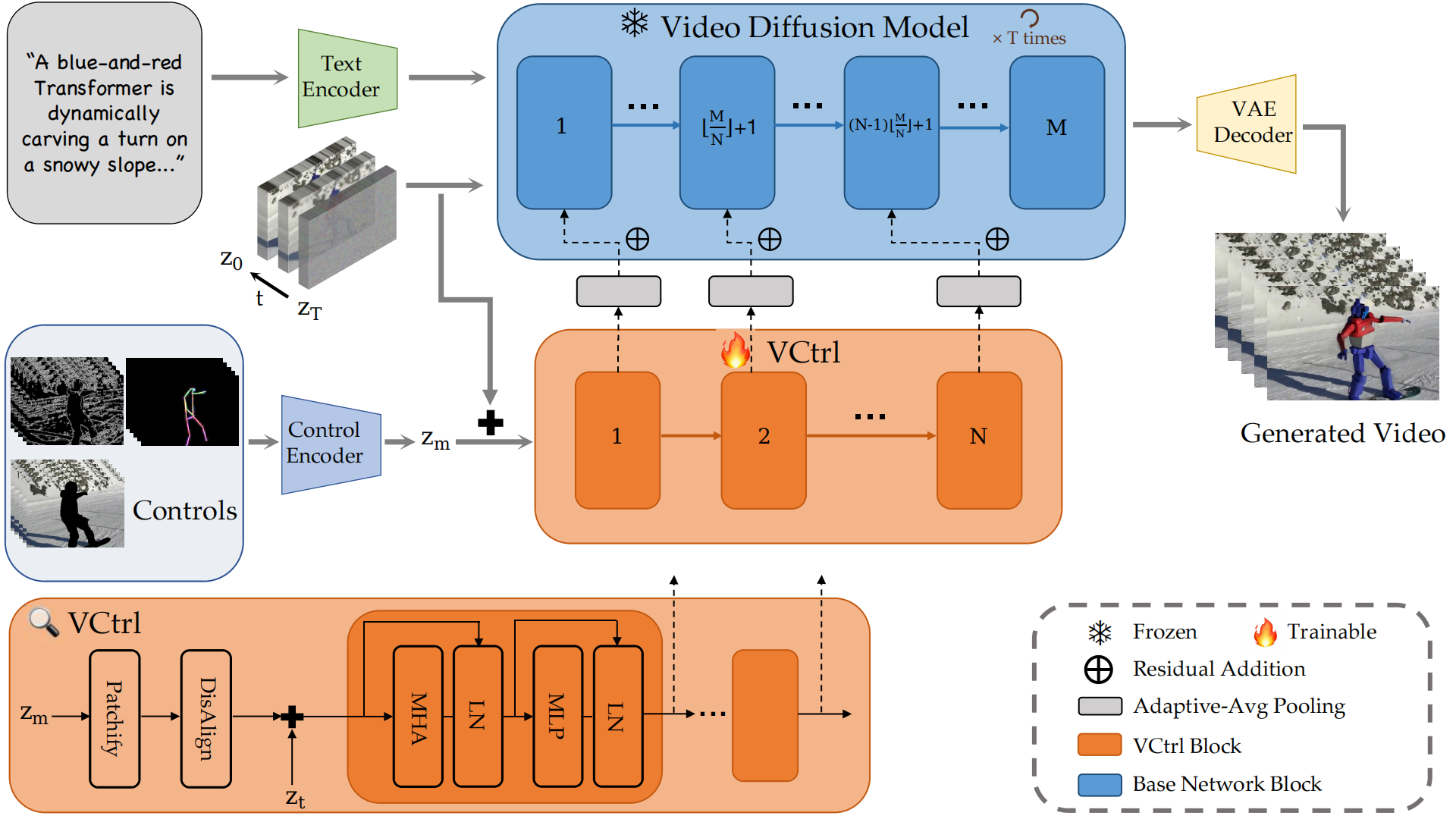
Overview architecture of VCtrl. A control signal (e.g., Canny edges, semantic masks, or pose keypoints) is first encoded by the control encoder. The resulting representation is then additively combined with latent and incorporated into the Video Diffusion Model via the proposed VCtrl module, which leverages a sparse residual connection mechanism. After several iterative denoising steps, the refined latent is decoded by a pretrained VAE to produce the final video.